I recently acquired a new development laptop and moved a number of local Git repositories from my old machine to my new machine. In doing so I also changed the folder structure, and when trying to run some code I was presented with this Python error:
import file mismatch: imported module 'tests.desktop.consumer_pages.test_details_page' has this __file__ attribute: /Users/bsilverberg/gitRepos/marketplace-tests/tests/desktop/consumer_pages/test_details_page.py which is not the same as the test file we want to collect: /Users/bsilverberg/Documents/gitRepos/marketplace-tests/tests/desktop/consumer_pages/test_details_page.py HINT: remove __pycache__ / .pyc files and/or use a unique basename for your test file modules
This was a symptom of the fact that Python creates .pyc files on my machine when it compiles code. This can result in other nastiness too, as well as cluttering up your machine, so I wanted to both delete all of these files and also prevent Python from doing it in the future. This post contains info on how to do both.
Deleting all .pyc files from a folder
You can use the find command (on OS X and Linux) to locate all of the .pyc files, and then use its delete option to delete them.
The command to find all .pyc files in all folders, starting with the current one is: find . -name '*.pyc'
If you want to delete all the files found, just add the -delete option: find . -name '*.pyc' -delete
Obviously, this can be used for any file type that you wish to eradicate, not just .pyc files.
Preventing Python from writing .pyc files
I don’t like having all of those extra files cluttering my machine, and, in addition to the error I mentioned above, I have from time to time seen other errors related to out of date .pyc files.
Another issue that .pyc files can cause is that they can be orphaned, for example if you remove a .py file from your project, but the .pyc file remains (which can happen as one often adds *.pyc to .gitignore). Python can then still pick up the module from the .pyc file via an import which can lead to difficult to diagnose bugs.
For these reasons I want to prevent Python from ever writing those files again. To do this all you have to do is set the environment variable PYTHONDONTWRITEBYTECODE to 1. You can ensure that that variable is set for any bash session that you start by adding the following to your .bash_profile or .bashrc: export PYTHONDONTWRITEBYTECODE=1
Dealing with images is not a trivial task. To you, as a human, it’s easy to look at something and immediately know what is it you’re looking at. But computers don’t work that way.
Tasks that are too hard for you, like complex arithmetics, and math in general, is something that a computer chews without breaking a sweat. But here the exact opposite applies — tasks that are trivial to you, like recognizing is it cat or dog in an image are really hard for a computer. In a way, we are a perfect match. For now at least.
While image classification and tasks that involve some level of computer vision might require a good bit of code and a solid understanding, reading text from a somewhat well-formatted image turns out to be a one-liner in Python —and can be applied to so many real-life problems.
And in today’s post, I want to prove that claim. There will be some installation to go though, but it shouldn’t take much time. These are the libraries you’ll need:
OpenCV
PyTesseract
I don’t want to prolonge this intro part anymore, so why don’t we jump into the good stuff now.
OpenCV
Now, this library will only be used to load the images(s), you don’t actually need to have a solid understanding of it beforehand (although it might be helpful, you’ll see why).
According to the official documentation:
OpenCV (Open Source Computer Vision Library) is an open source computer vision and machine learning software library. OpenCV was built to provide a common infrastructure for computer vision applications and to accelerate the use of machine perception in the commercial products. Being a BSD-licensed product, OpenCV makes it easy for businesses to utilize and modify the code.[1]
In a nutshell, you can use OpenCV to do any kind of image transformations, it’s fairly straightforward library.
If you don’t already have it installed, it’ll be just a single line in terminal:
pip install opencv-python
And that’s pretty much it. It was easy up until this point, but that’s about to change.
PyTesseract
What the heck is this library? Well, according to Wikipedia:
Tesseract is an optical character recognition engine for various operating systems. It is free software, released under the Apache License, Version 2.0, and development has been sponsored by Google since 2006.[2]
I’m sure there are more sophisticated libraries available now, but I’ve found this one working out pretty well. Based on my own experience, this library should be able to read text from any image, provided that the font isn’t some bulls*** that even you aren’t able to read.
If it can’t read from your image, spend more time playing around with OpenCV, applying various filters to make the text stand out.
Now the installation is a bit of a pain in the bottom. If you are on Linux it all boils down to a couple of sudo-apt get commands:
I’m on Windows, so the process is a bit more tedious.
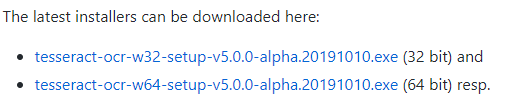
First, open up THIS URL, and download 32bit or 64bit installer:
The installation by itself is straightforward, boils down to clicking Next a couple of times. And yeah, you also need to do a pip installation:
pip install pytesseract
Is that all? Well, no. You still need to tell Python where Tesseract is installed. On Linux machines, I didn’t have to do so, but it’s required on Windows. By default, it’s installed in Program Files.
If you did everything correctly, executing this cell should not yield any error:
Is everything good? You may proceed.
Reading the Text
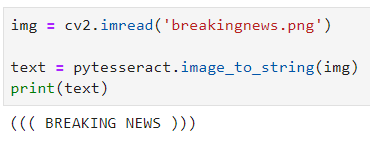
Let’s start with a simple one. I’ve found a couple of royalty-free images that contain some sort of text, and the first one is this:
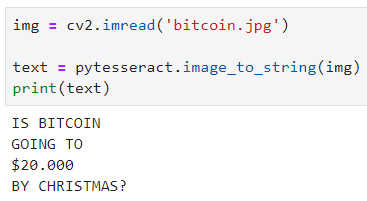
Now it’s up to you to apply this to your own problem. OpenCV skills could be of vital importance here if the text blends with the background.
Before you leave
Reading text from an image is a pretty difficult task for a computer to perform. Think about it, the computer doesn’t know what a letter is, it only works only with numbers. What happens behind the hood might seem like a black box at first, but I encourage you to investigate further if this is your area of interest.
I’m not saying that PyTesseract will work perfectly every time, but I’ve found it good enough even on some trickier images. But not straight out of the box. Some image manipulation is required to make the text stand out.
It’s a complex topic, I know. Take it one day at a time. One day it will be second nature to you.
I have used a local image "tux.jpg" so, you can use anything that has true image format. Let me clarify the codes above.
Step 1: I have defined function read_string() and opened the image in rb mode. The variable image_string that inside of the function holds base64 string.
I have used the other function inside this function to get image string and the other function returns image string as you know. Anyways so base64_string variable holds image string in base64 format and decoded. The last I have used Image function from PIL to show image.
👉
if__name__=="__main__":decode_base64()
When I call the function decode_base64() the image will be open.